Root Cause Analysis
Contents
Root Cause Analysis#
Root cause analysis (RCA) is a process used in IT to identify the underlying cause of a problem. By identifying the root cause, IT professionals can develop a solution that addresses the problem at its source, rather than simply treating the symptoms. Root cause analysis typically involves breaking down a problem into smaller pieces and then systematically investigating each piece to identify the root cause. This process can be used to identify problems with hardware, software, processes, or any other aspect of IT.
Important
Root cause analysis is the most important problem solving skill in IT and cybersecurity. It’s so important that we created a special section for it!
When should I used a structured RCA technique?#
There are two main approaches to problem solving: the intuitive approach and the structured approach. The intuitive approach is more flexible and relies on our natural ability to see patterns and relationships. The structured approach is more rigid and relies on a step-by-step process to find a solution. The intuitive approach is often quicker and can be more creative, but it can also be less reliable. The structured approach is usually slower, but it can be more reliable. Which approach is best depends on the problem at hand.
If you encounter an IT issue, such as a software bug, you should first try to resolve it intuitively. However, you should only try this for 20 minutes the first time. If you are unable to resolve the issue in this amount of time, you must switch to a structured approach. It may take 1-3 hours to address a challenging problem using a structured approach. Though these issues are uncommon, a truly challenging situation can take many days to solve. Asking the community for assistance is the next step if structured RCA doesn’t work.

What are the steps in an RCA technique?#
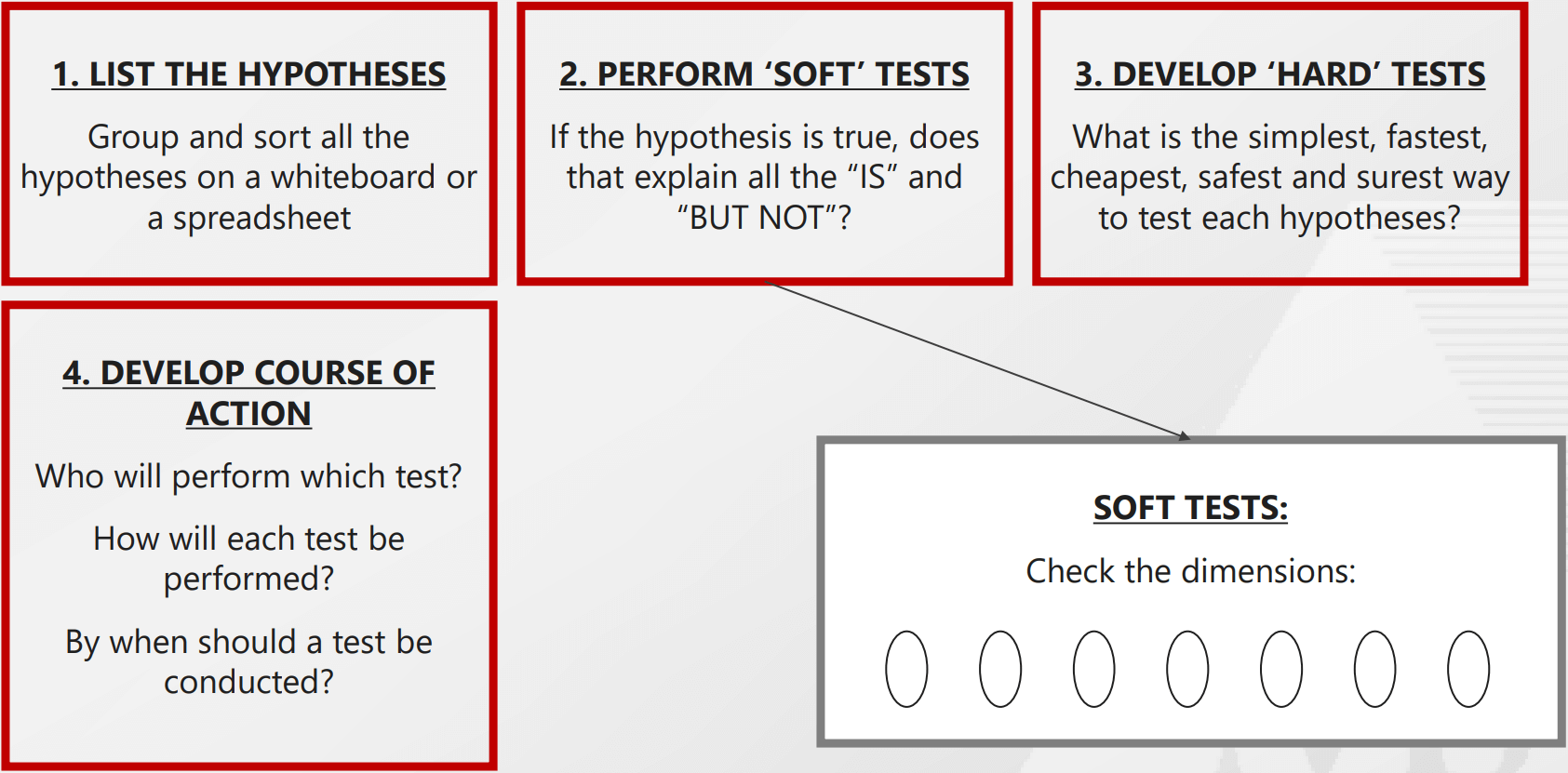
The following diagram shows an overview of the root-cause analysis process:

Step 1 - Develop an incident statement
When troubleshooting an incident, it is important to first gather all of the relevant information in order to identify the root cause of the problem. This information can be gathered through an incident statement. An incident statement is simply a record of what happened, when it happened, and any relevant details that may help to identify the cause of the problem.
Here’s a simple template for an incident statement:

Note that this methodology can be used to investigate a wide range of IT problems, including cyber intrusions.
Step 2 - Identify all of the incident’s dimensions
There are many different dimensions to an incident. The most common dimensions are the who, what, when, where, why, and how. These dimensions can help to provide a more comprehensive understanding of an incident.
Dimension 1: Object affected
Dimension 2: Type of incident
Dimension 3: Users impacted
Dimension 4: Users location
Dimension 5: Incident location
Dimension 6: Time and date of the incident
Dimension 7: Pattern of occurrence
Dimension 8: Unique attributes
Feel free to add more dimensions. Every incident is unique so you should adapt the process to the problem you are facing.
Here’s an example of how “dimensioning” an incident looks like:

Step 3 - Generate hypotheses and test them
When troubleshooting software, it is important to generate hypotheses and test them. This will help to identify the root cause of the problem and find a solution. One way to generate hypotheses is to brainstorm potential causes of the problem. Once you have a list of potential causes, you can then test each one to see if it is the actual cause of the problem. To test a hypothesis, you can try to reproduce the problem and see if the hypothesis is correct. If you are unable to find the root cause of the problem, it may be necessary to ask for help from others who are more experienced.
Whiteboard Example#
The following image shows how RCA is put in practice on a whiteboard:
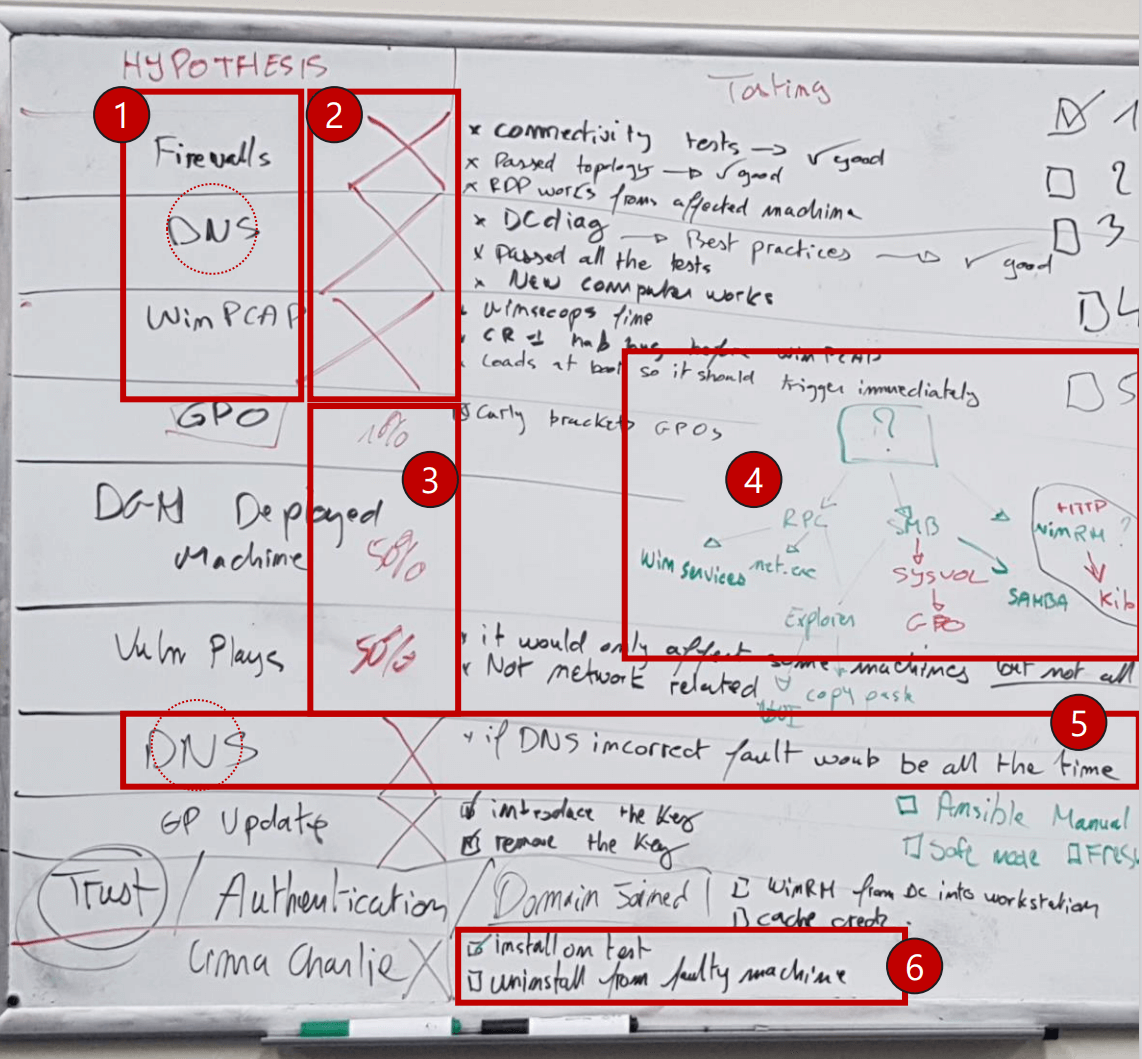
Some key points that are highlighted:
This is a list of hypotheses generated that may explain the fault
In this column, we crossed the hypotheses that were disproved
Testing of some hypotheses was in progress, “50%” is how many test ideas were ruled out
This is Dependency Tree - what triggers the fault, what does not, why not?
An example of a hypothesis that was ruled out without testing, through pure logic
Examples of tests for a hypothesis
Where can I go for help if RCA doesn’t work?#
We have found that RCA always succeeds. When it doesn’t, it’s because the practitioner didn’t use the technique correctly or didn’t fully comprehend the fault (i.e., it has not been properly dimensioned). In such cases, the following resources will prove helpful:
Stackoverflow A public platform to ask coding questions
Serverfault A question and answer site for system and network administrators
MCSI Forums on Discord