Content Discovery - Part 1
Contents
Content Discovery - Part 1#
The first stage in attacking software is obtaining and analyzing critical information about it in order to acquire a better grasp of what you’re dealing with. We can find information either manually, with the help of automated tools, or with Open-Source Intelligence (OSINT). This blog article will introduce you to discovering website content using automated tools.
Simple excercise - Manual disclosure of Robots.txt#
Some spidering (which is also referred as the process of indexing website content) tools designed to attack web applications look for the robots.txt file. Now let’s discover this file manually. First, here is a quick definition.
What is Robots.txt file?
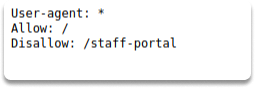
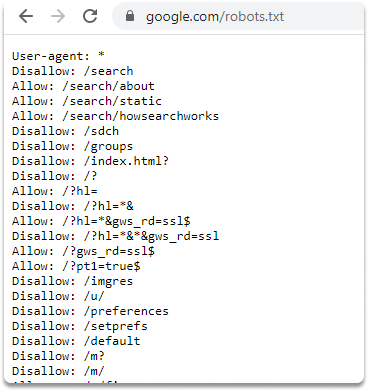
The robots.txt file is a text file that instructs search algorithms which pages to display in their internet search results, or it prevents particular search engines from indexing the entire website. These pages might be administration portals or files for the website’s consumers. This file provides us with a comprehensive list of website sites that the owners do not want us to find as penetration testers.
How to manually check Robots.txt file
You can simply type the IP address or the name of the website you want to discover on your web browser. And add backslash robots.txt as in the example:
/robots.txt

Conclusion#
As we have covered, manual browsing identifies the bulk of the material and functionality in a typical program. However, with the help of a variety of manual and automated tools, you can disclose relevant content and functionality that is restricted for regular users.
Now, by examining the robots.txt file, you already know which content is not allowed to be viewed by web crawlers.
See also
Want to learn practical Secure Software Development skills? Enrol in MASE - Certified Application Security Engineer