Fog Computing
Contents
Fog Computing#
Fog computing is a distributed form of cloud computing – this means that the workload is performed in the cloud, but as part of a distributed, decentralized architecture. In practice, this means that compute is moved towards edge nodes and away from centralised servers. The most popular use case for fog computing is probably IoT, an area which is growing exponentially at present.
What is Fog Computing?#
Fog computing, also known as edge computing, is a decentralized computing paradigm that extends cloud computing capabilities to the edge of the network. It aims to bring computing resources closer to the data source and end-users, reducing latency and enabling real-time processing and analysis of data. In fog computing, data is processed and stored at various points in the network hierarchy, such as routers, switches, and gateways, rather than solely relying on centralized cloud servers. As compared to the concept of “the cloud” the idea of “fog” refers to the way that fog is generally more distributed than a cloud – hopefully that helps you visualise what we mean!
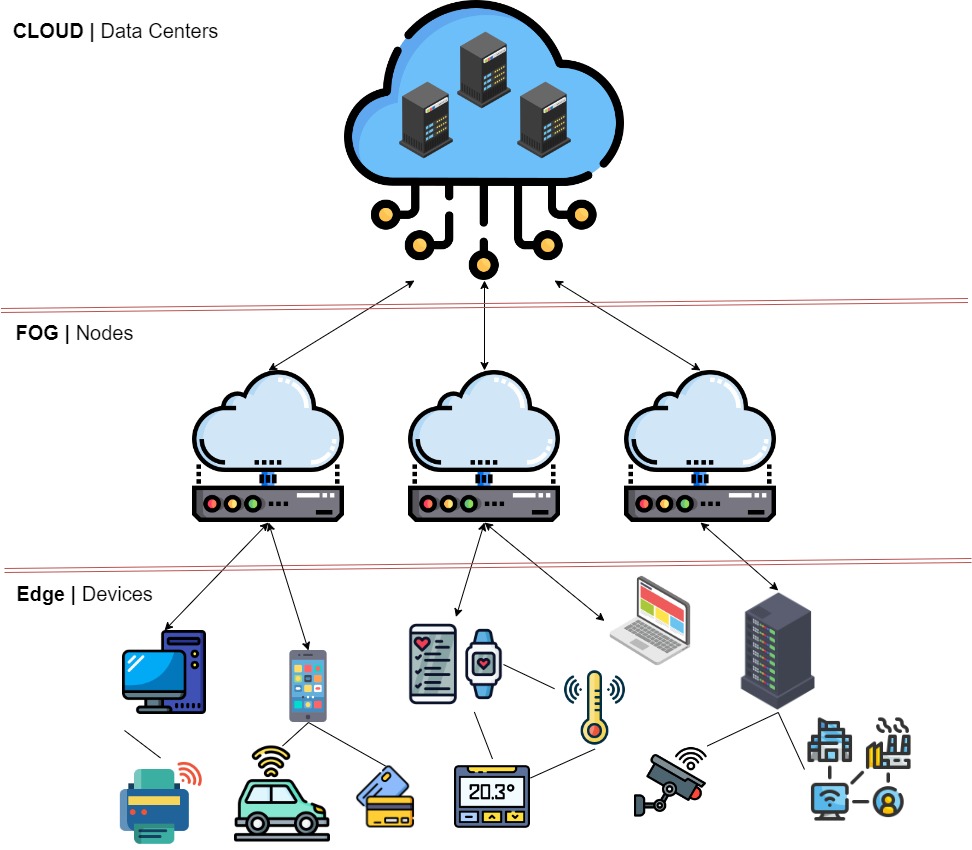
Problems Solved by Fog Computing#
Fog computing is mainly of interest because of the way it addresses the challenges posed by the explosive growth of IoT (Internet of Things) devices and the need for rapid data analysis. Traditional cloud computing models struggle with latency issues when processing data from numerous IoT devices, even when using high performance networks and compute. By moving computation closer to the data source, fog computing minimizes data transfer delays and allows faster response times, making it particularly useful for applications that require real-time analytics and decision-making. Of course, edge devices tend to have less compute power than purpose built cloud compute, however if each element in a fog network performs a small amount of compute the lack of processing power can be offset with the volume of nodes.
Advantages of Fog Computing#
The main advantages of a fog computing approach are:
Low Latency - Fog computing significantly reduces latency by processing data closer to where it’s generated, enabling real-time applications such as video streaming and autonomous vehicles.
Bandwidth Optimization - By filtering and processing data locally, fog computing reduces the amount of data that needs to be sent to the cloud, optimizing bandwidth usage.
Improved Privacy - Local processing means sensitive data can be processed locally without necessarily being transmitted to a remote cloud server, enhancing privacy and data security. This of course, also depends on the secure configuration of the fog node!
Scalability - Fog computing can, by its very nature, scale to handle the growing number of edge devices, improving the overall efficiency of data processing and analytics.
Resilience - Distributed architecture makes fog systems more resilient to failures and outages, as tasks can be rerouted to other nearby devices.
Disadvantages of Fog Computing#
As always, there’s also some downsides with fog computing to be aware of – the most important are:
Complex Management - Managing a distributed network of edge devices requires careful orchestration and coordination, which can be complex. Automation can help a great deal here, but troubleshooting can be more challenging.
Limited Resources - Edge devices might have limited computing power and memory, which could constrain the complexity of tasks they can handle. If there are not enough other devices to take up the slack there may not be enough power available.
Security Concerns - Distributing data and processing across various devices raises security challenges, potentially increasing the attack surface.
Security Concerns with Fog Computing#
Fundamentally, distributing data over a wider area and more systems serves to increase the attack surface – the more nodes are involved in a system, the more points of possible attack there are. This raises several challenges which security professionals need to be aware of, these include:
Data Exposure - Distributing data across various devices increases the risk of unauthorized access or data exposure if proper security measures aren’t in place. While a smaller subset of data may exist on any one device, and therefore less data stands to be exposed in any once incident, this is usually little consolation from a regulatory or reputational perspective if a breach occurs!
Device Vulnerabilities - Edge devices might have security vulnerabilities that can be exploited by malicious actors to gain access to the network. Edge devices are often less expensive, and while it’s not fair to say that all low cost devices suffer from poor security, many do.
Data Integrity - Ensuring data integrity becomes more challenging when data is processed and stored across different devices with varying levels of security.
Authentication and Authorization - Managing user access and authentication across a distributed environment requires robust security protocols to prevent unauthorized access.
An Example Application of Fog Computing - Industrial Internet of Things (IIoT) in Manufacturing#
Consider a manufacturing facility that embraces the Industrial Internet of Things (IIoT) to optimize its operations. With sensors and devices spread throughout the factory floor, an immense volume of data is generated in real-time, capturing machine performance, temperature, and production metrics - this can be hugely beneficial to optimise processes, but there’s a lot of data to work through.
Fog computing can help here - by deploying fog nodes within the manufacturing facility, data can be processed locally before being sent to a centralized server, or up to the cloud. Each fog node collects data from nearby sensors, performs immediate analysis, and responds in real-time. For instance, a fog node monitoring a production line might detect a machine running at suboptimal efficiency. Instead of waiting for data to travel to a remote cloud server, the fog node can trigger adjustments locally to recalibrate the machine’s performance in seconds.
By processing data closer to the source, the manufacturing facility achieves ultra-low latency, ensuring that actions are taken without delay. This enhances production efficiency, minimizes downtime, and reduces the risk of costly machinery breakdowns. Moreover, the localized processing conserves network bandwidth, as only relevant data is sent to the cloud for long-term analysis, leading to better bandwidth utilization and cost savings.
Final words#
Fog computing is a newer and interesting approach to addressing the challenges posed by the surge of IoT devices and the need for real-time data analysis. By distributing computation and data storage closer to the source, fog computing can help to optimise latency, bandwidth, and privacy while introducing new considerations for security and management. Organizations should weigh the advantages against the potential disadvantages to determine whether fog computing aligns with their specific operational, and especially security needs, however as more applications opt for a distributed approach fog computing may well become much more popular.